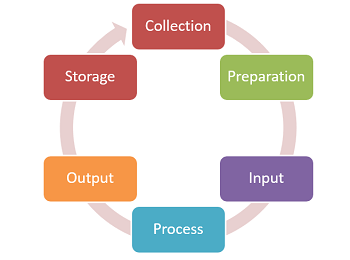
Concept of data processing
Data processing refers to the manipulation and transformation of raw data into meaningful and useful information. It involves various steps and techniques to organize, analyze, and present data in a structured and coherent manner. Data processing plays a crucial role in decision-making, problem-solving, and gaining insights from large volumes of information.
The process of data processing typically involves the following key stages:
- Data Collection: This is the initial step where raw data is gathered from various sources, such as sensors, surveys, databases, websites, and more. The collected data can be in various formats, including text, numbers, images, audio, and video.
- Data Cleaning: Raw data often contains errors, inconsistencies, missing values, and other issues. Data cleaning involves identifying and rectifying these problems to ensure accurate and reliable results.
- Data Transformation: Once the data is cleaned, it may need to be transformed or converted into a common format for analysis. This might involve converting units, normalizing values, aggregating data, or applying other operations to make the data more suitable for analysis.
- Data Analysis: This stage involves applying various techniques, such as statistical analysis, data mining, machine learning, and other algorithms, to extract insights, patterns, and relationships from the processed data. The goal is to discover valuable information that can support decision-making.
- Data Visualization: Communicating the results of data analysis effectively is important. Data visualization uses graphical representations like charts, graphs, maps, and dashboards to present complex data in a visually intuitive way, making it easier for people to understand and interpret.
- Interpretation and Insights: The processed and analyzed data is then interpreted to draw meaningful conclusions and insights. These insights can help answer questions, identify trends, make predictions, and support informed decision-making.
- Reporting and Presentation: The final step involves creating reports, presentations, or summaries that convey the findings and insights derived from the data processing and analysis. These reports may be used to inform stakeholders, managers, or other relevant parties.
Data processing can take place using various technologies and tools, such as spreadsheets, databases, programming languages (Python, R, etc.), business intelligence software, and specialized data processing platforms. The specific techniques and tools used depend on the complexity of the data, the goals of the analysis, and the resources available.
With the advent of big data, advanced analytics, and machine learning, data processing has become more sophisticated and capable of handling large-scale datasets and complex analyses, leading to deeper insights and improved decision-making processes in various fields such as business, science, healthcare, finance, and more.
What is required Concept of data processing
The concept of data processing encompasses several key requirements that ensure effective and meaningful transformation of raw data into valuable information. These requirements help guide the data processing process to achieve accurate, reliable, and actionable results. Here are some essential requirements for successful data processing:
- Accuracy and Quality: Accurate data is fundamental to reliable insights. Data processing should involve thorough data cleaning, validation, and verification processes to identify and rectify errors, inconsistencies, and outliers. High data quality ensures that the processed information is trustworthy and suitable for decision-making.
- Relevance: Focus on collecting and processing data that is relevant to the objectives of the analysis. Unnecessary or irrelevant data can lead to noise and confusion in the results. Clearly define the goals of data processing to guide data collection efforts.
- Timeliness: Process data in a timely manner to maintain its relevance and usefulness. Depending on the context, real-time or near-real-time processing might be essential to support quick decision-making or to monitor rapidly changing situations.
- Consistency: Ensure consistency in data processing methods and techniques. This includes using standardized procedures for data cleaning, transformation, and analysis to avoid discrepancies and enhance comparability across different datasets.
- Privacy and Security: Protect sensitive and private data throughout the processing pipeline. Implement measures to anonymize or pseudonymize data, adhere to relevant data protection regulations (e.g., GDPR), and prevent unauthorized access or breaches.
- Scalability: Data processing should be scalable to handle varying data volumes and accommodate growth. This is particularly important as data sources expand and new data types are integrated into the analysis.
- Flexibility: The ability to adapt to changing requirements and data sources is crucial. Data processing pipelines should be designed to accommodate changes in data formats, sources, and analysis techniques without requiring extensive rework.
- Data Governance: Establish clear data governance policies to define roles, responsibilities, and ownership of data processing activities. This ensures accountability and consistency in data handling practices.
- Documentation: Maintain comprehensive documentation of the data processing steps, methodologies, and assumptions. This documentation aids in replicating analyses, validating results, and addressing potential questions or concerns.
- Interoperability: Data processing systems should be compatible with other tools, platforms, and systems used in the organization. This enables seamless integration of processed data
When is required Concept of data processing
The concept of data processing is required in various situations and industries where there is a need to collect, organize, analyze, and interpret data to derive meaningful insights, make informed decisions, and solve problems. Here are some scenarios where the concept of data processing is essential:
- Business Decision-Making: Companies collect and process data to understand customer preferences, market trends, and operational efficiency. This information guides strategic decisions, product development, marketing campaigns, and resource allocation.
- Healthcare: Medical institutions use data processing to manage patient records, analyze medical imaging, conduct clinical trials, and enhance diagnosis and treatment planning.
- Finance and Banking: Financial institutions rely on data processing for risk assessment, fraud detection, investment strategies, credit scoring, and regulatory compliance.
- Manufacturing and Supply Chain: Data processing optimizes production processes, tracks inventory, predicts maintenance needs, and ensures efficient supply chain management.
- Scientific Research: Researchers use data processing to analyze experimental results, simulate complex phenomena, and uncover insights in fields like physics, astronomy, biology, and climate science.
- E-commerce: Online retailers use data processing to provide personalized product recommendations, analyze shopping behavior, and optimize inventory management.
- Social Media and Marketing: Social media platforms process user interactions and engagement to deliver relevant content and targeted advertisements.
- Logistics and Transportation: Data processing is crucial for route optimization, vehicle tracking, and demand forecasting in logistics and transportation industries.
- Energy Management: Utility companies process data from smart meters and sensors to optimize energy distribution, monitor consumption patterns, and improve energy efficiency.
- Agriculture: Precision agriculture relies on data processing to monitor soil conditions, weather patterns, and crop health for optimized planting and harvesting.
- Government and Public Services: Governments use data processing for census analysis, public safety, urban planning, disaster response, and policy formulation.
- Education: Educational institutions use data processing to track student performance, personalize learning experiences, and analyze educational trends.
- Entertainment and Media: Streaming platforms process user viewing habits to recommend content, understand audience preferences, and optimize content delivery.
- Environmental Monitoring: Data processing supports environmental studies by analyzing data from sensors, satellites, and weather stations to monitor climate changes and ecological health.
- Health and Fitness Tracking: Wearable devices and health apps process user data to track physical activity, monitor vital signs, and offer personalized health recommendations.
In essence, the concept of data processing is required whenever there is a need to convert raw data into valuable insights that inform decision-making, enhance efficiency, drive innovation, and improve overall outcomes. It’s a foundational process that has become increasingly critical as the world becomes more data-driven.
The concept of data processing is required in numerous industries, sectors, and everyday situations where data is collected, analyzed, and transformed into meaningful information for various purposes. Here are some specific areas where the concept of data processing is essential:
- Business and Commerce:
- Market Research: Analyzing consumer behavior and market trends to make informed business decisions.
- Sales and Marketing: Targeted advertising, customer segmentation, and campaign optimization.
- Inventory Management: Tracking stock levels, reorder points, and supply chain efficiency.
- Customer Relationship Management (CRM): Managing customer interactions and enhancing customer experience.
- Healthcare and Medicine:
- Patient Records: Storing and managing electronic health records (EHR) for accurate patient care.
- Medical Imaging: Analyzing X-rays, MRI scans, and other medical images for diagnosis.
- Drug Development: Analyzing clinical trial data for drug efficacy and safety assessment.
- Finance and Banking:
- Fraud Detection: Identifying unusual patterns or behaviors in financial transactions.
- Risk Assessment: Evaluating creditworthiness and investment risks.
- Algorithmic Trading: Making high-frequency trading decisions based on market data.
- Manufacturing and Engineering:
- Quality Control: Ensuring product quality by analyzing manufacturing data.
- Predictive Maintenance: Identifying maintenance needs based on equipment sensor data.
- Process Optimization: Improving efficiency and reducing waste through data analysis.
- Transportation and Logistics:
- Route Optimization: Finding the most efficient routes for deliveries and shipments.
- Vehicle Tracking: Monitoring vehicle locations, speed, and performance.
- Demand Forecasting: Predicting demand for transportation services.
- Social Media and Entertainment:
- Content Recommendation: Providing personalized content recommendations to users.
- User Engagement Analysis: Understanding user interactions and engagement patterns.
- Box Office Predictions: Predicting movie or TV show box office performance.
- Environmental Monitoring:
- Climate Research: Analyzing climate data to study global temperature changes.
- Pollution Monitoring: Tracking pollution levels in air, water, and soil.
- Education and Research:
- Learning Analytics: Analyzing student performance and engagement in educational settings.
- Scientific Research: Processing experimental data to derive scientific insights.
- Government and Public Services:
- Census and Demographics: Analyzing population data for policy-making and resource allocation.
- Public Safety: Analyzing crime data for law enforcement strategies.
- Agriculture:
- Precision Farming: Using data to optimize irrigation, fertilization, and planting.
- Crop Monitoring: Analyzing sensor data for crop health assessment.
- Energy and Utilities:
- Smart Grids: Optimizing energy distribution based on real-time consumption data.
- Energy Consumption Analysis: Analyzing energy use patterns to promote efficiency.
- Health and Fitness Tracking:
- Wearable Devices: Processing data from fitness trackers and health monitors.
- Diet and Exercise Planning: Creating personalized plans based on user data.
These examples highlight just a fraction of the areas where the concept of data processing is required. Essentially, data processing is relevant wherever there is a need to gather, transform, and analyze data to gain insights, make informed decisions, and improve outcomes.
Case study on Concept of data processing
Case Study: Data Processing in E-Commerce for Personalized Recommendations
1. Introduction
In the era of digitalization, e-commerce platforms are facing an enormous influx of data generated by user interactions, transactions, and browsing behavior. To enhance user experience and boost sales, personalized recommendations have become an integral part of these platforms. This case study explores how an e-commerce company utilizes data processing techniques to provide personalized product recommendations to its customers.
2. Business Challenge
The e-commerce company, “Tech Mart,” aims to increase customer engagement and conversion rates by offering personalized product recommendations. However, with millions of products and a vast customer base, manually curating recommendations for each user is impractical. The challenge is to implement an automated system that processes user data and generates accurate recommendations in real-time.
3. Data Collection
TechMart collects various types of data from its users:
- User Profile Data: This includes basic information like name, age, gender, location, and purchase history.
- Browsing Behavior: Data on products a user views, time spent on each product page, and products added to their cart.
- Purchase History: Information about previous purchases, including product categories and brands.
4. Data Processing Pipeline
Tech Mart implements a data processing pipeline to deliver personalized recommendations:
Step 1: Data Collection and Storage
- Raw data from various sources (website, app, purchase logs) is collected and stored in a data warehouse.
Step 2: Data Cleaning and Preprocessing
- Data is cleaned, normalized, and transformed into a consistent format to remove inconsistencies and errors.
Step 3: Data Integration
- Different types of data (user profiles, browsing behavior, purchase history) are integrated to create a comprehensive user profile.
Step 4: Feature Extraction
- Relevant features are extracted from the integrated data, such as popular product categories, frequently browsed brands, and user preferences.
Step 5: Machine Learning Model Training
- A machine learning model is trained using historical data, including user profiles and their corresponding purchase or interaction history.
- Collaborative filtering, content-based filtering, or hybrid models can be employed for recommendation generation.
Step 6: Real-time Recommendation Generation
- As users interact with the platform, their data is fed into the trained model.
- The model generates real-time recommendations based on the user’s profile and behavior.
5. Implementation and Benefits
TechMart’s implementation of personalized recommendations results in several benefits:
- Enhanced User Experience: Users are presented with products tailored to their preferences, increasing the likelihood of making a purchase.
- Increased Sales: Personalized recommendations lead to higher conversion rates as users discover products aligned with their interests.
- Improved Customer Engagement: Users spend more time on the platform due to relevant product suggestions, leading to increased brand loyalty.
- Data-Driven Insights: The data collected from user interactions can provide insights into emerging trends, popular products, and user preferences.
6. Challenges and Considerations
- Data Privacy: Ensure compliance with data protection regulations and maintain user privacy while collecting and processing data.
- Scalability: As the user base grows, the data processing pipeline must be scalable to handle increased data volume.
- Model Accuracy: Continuous monitoring and fine-tuning of the recommendation model are necessary to ensure accurate and up-to-date suggestions.
- Bias Mitigation: Prevent algorithmic biases that might lead to unfair recommendations based on user demographics.
7. Conclusion
Data processing plays a crucial role in enabling e-commerce companies like TechMart to deliver personalized recommendations to their customers. By collecting, processing, and analyzing user data, these platforms can enhance user experience, drive sales, and gain valuable insights into customer behavior. The successful implementation of such a system requires a robust data processing pipeline, a well-trained recommendation model, and careful consideration of ethical and privacy concerns.
White paper on Concept of data processing
White Paper: The Concept of Data Processing
Abstract: Data processing is a fundamental concept in the world of technology and information management. It involves a series of actions and transformations that convert raw data into meaningful information. This white paper provides an in-depth exploration of the concept of data processing, its various stages, methods, applications, and implications in today’s data-driven landscape.
1. Introduction:
In an era marked by the proliferation of digital information, data processing has emerged as a critical component of modern business, science, and everyday life. Data processing encompasses a range of activities that transform raw data into structured and actionable insights. From collecting and organizing data to analyzing and interpreting it, the data processing journey is central to decision-making, problem-solving, and innovation across industries.
2. Stages of Data Processing:
2.1. Data Collection: The data processing journey begins with data collection. Data can originate from various sources, including sensors, user interactions, surveys, and more. This stage involves gathering raw data in its original format, which may include text, numbers, images, audio, or video.
2.2. Data Preprocessing: Raw data is often noisy, inconsistent, and unstructured. Data preprocessing involves cleaning, transforming, and organizing the data to ensure its quality and usability. This stage includes tasks such as removing duplicates, handling missing values, and standardizing formats.
2.3. Data Storage: Processed data is stored in databases or data warehouses. Structured storage allows for efficient retrieval, management, and analysis of data. Different types of databases, including relational, NoSQL, and data lakes, are used based on the nature of the data and the specific requirements.
2.4. Data Transformation: Data transformation involves converting data from one format or structure to another. This may include aggregating data, performing calculations, and creating new variables or features that are more suitable for analysis.
2.5. Data Analysis: Data analysis is the heart of data processing. It involves applying statistical, mathematical, and computational techniques to derive insights from the processed data. Analysis methods can range from simple descriptive statistics to advanced machine learning algorithms.
2.6. Interpretation and Visualization: The insights gained from data analysis need to be interpreted in the context of the problem or question at hand. Visualization tools are often used to present the findings in a meaningful and understandable manner, aiding decision-makers in drawing conclusions.
3. Methods of Data Processing:
3.1. Batch Processing: Batch processing involves collecting and processing data in fixed-size chunks or batches. It is suitable for scenarios where data can be processed offline and does not require real-time analysis.
3.2. Real-time Processing: Real-time processing, also known as stream processing, involves analyzing and acting upon data as it is generated. This method is crucial for applications that require immediate responses, such as fraud detection or monitoring sensor data.
3.3. Parallel Processing: Parallel processing uses multiple processors or computing resources to process data simultaneously. This approach speeds up data processing for large datasets and complex computations.
4. Applications of Data Processing:
4.1. Business Intelligence: Data processing forms the foundation of business intelligence, enabling organizations to analyze customer behavior, market trends, and operational efficiency to make informed decisions.
4.2. Healthcare and Medicine: In the healthcare sector, data processing is used for patient records management, medical imaging analysis, drug discovery, and epidemiological studies.
4.3. Finance and Banking: Financial institutions rely on data processing for risk assessment, fraud detection, algorithmic trading, and customer segmentation.
4.4. Manufacturing and Supply Chain: Data processing optimizes production processes, supply chain management, quality control, and predictive maintenance in manufacturing.
4.5. Scientific Research: Researchers use data processing to analyze experimental results, simulate complex phenomena, and uncover insights in fields such as astronomy, biology, and climate science.
5. Implications and Challenges:
5.1. Privacy and Security: The processing of personal and sensitive data raises concerns about privacy and security. Regulations like GDPR and HIPAA dictate how data should be collected, processed, and stored to protect individuals’ rights.
5.2. Data Quality: The accuracy and reliability of processed data directly impact the quality of insights derived. Inaccurate or incomplete data can lead to faulty conclusions and flawed decision-making.
5.3. Bias and Fairness: Data processing algorithms can inadvertently perpetuate biases present in the original data. Careful attention is needed to ensure fairness and mitigate biases in analysis.
5.4. Scalability and Performance: As data volumes grow, processing speed and scalability become crucial. Ensuring that data processing systems can handle increasing loads is a constant challenge.
6. Conclusion:
Data processing is a foundational concept that underpins the modern information age. From enabling data-driven decisions to fueling innovation across industries, the process of collecting, cleaning, analyzing, and interpreting data has transformed the way we understand the world. As technology continues to evolve, so too will the methods and applications of data processing, reshaping the boundaries of what is possible in the realm of information management.