White Paper on Markup language & JSON
COURTESY :- vrindawan.in
Wikipedia
Markup language refers to a text-encoding system consisting of a set of symbols inserted in a text document to control its structure, formatting, or the relationship between its parts. Markup is often used to control the display of the document or to enrich its content to facilitating automated processing. A markup language is a set of rules governing what markup information may be included in a document and how it is combined with the content of the document in a way to facilitate use by humans and computer programs. The idea and terminology evolved from the “marking up” of paper manuscripts (i.e., the revision instructions by editors), which is traditionally written with a red pen or blue pencil on authors’ manuscripts.
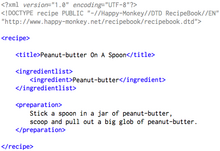
Older markup languages, which typically focus on typography and presentation, include troff, TeX, and La TeX. Scribe and most modern markup languages, for example XML, identify document components (for example headings, paragraphs, and tables), with the expectation that technology such as style sheets will be used to apply formatting or other processing.
Some markup languages, such as the widely used HTML, have pre-defined presentation semantics, meaning that their specification prescribes some aspects of how to present the structured data on particular media. HTML, like Doc Book, Open eBook, JATS, and many others is based on the markup meta-languages SGML and XML. That is, SGML and XML allow designers to specify particular schemas, which determine which elements, attributes, and other features are permitted, and where.
One extremely important characteristic of most markup languages is that they allow intermingling markup with document content such as text and pictures. For example, if a few words in a sentence need to be emphasized, or identified as a proper name, defined term, or another special item, the markup may be inserted between the characters of the sentence. This is quite different structurally from traditional databases, where it is by definition impossible to have data that is within a record but not within any field. Furthermore, markup for human-readable texts must maintain order: it would not suffice to make each paragraph of a book into a “paragraph” record, where those records do not maintain order.
The noun markup is derived from the traditional publishing practice called “marking up” a manuscript, which involves adding handwritten annotations in the form of conventional symbolic printer’s instructions — in the margins and the text of a paper or a printed manuscript.
For centuries, this task was done primarily by skilled typographers known as “markup men” or “d markers” who marked up text to indicate what typeface, style, and size should be applied to each part, and then passed the manuscript to others for typesetting by hand or machine.
The markup was also commonly applied by editors, proofreaders, publishers, and graphic designers, and indeed by document authors, all of whom might also mark other things, such as corrections, changes, etc.
There are three main general categories of electronic markup, articulated in Coombs, Renear, and De Rose (1987), and Bray (2003).
The kind of markup used by traditional word-processing systems: binary codes embedded within document text that produce the WYSIWYG (“what you see is what you get“) effect. Such markup is usually hidden from human users, even authors and editors. Properly speaking, such systems use procedural and/or descriptive markup underneath but convert it to “present” to the user as geometric arrangements of type.
Markup is embedded in text which provides instructions for programs to process the text. Well-known examples include troff, TeX, and Markdown. It is assumed that software processes the text sequentially from beginning to end, following the instructions as encountered. Such text is often edited with the markup visible and directly manipulated by the author. Popular procedural markup systems usually include programming constructs, especially macros, allowing complex sets of instructions to be invoked by a simple name (and perhaps a few parameters). This is much faster, less error-prone, and more maintenance-friendly than re-stating the same or similar instructions in many places.
JSON is a language-independent data format. It was derived from JavaScript, but many modern programming languages include code to generate and parse JSON-format data. JSON filenames use the extension .json. Any valid JSON file is a valid JavaScript (.js) file, even though it makes no changes to a web page on its own.
![]()
Douglas Crock ford originally specified the JSON format in the early 2000s. He and Chip Morning star sent the first JSON message in April 2001.
The acronym originated at State Software, a company co-founded by Douglas Crockford and others in March 2013.
The 2017 international standard (ECMA-404 and ISO/IEC 21778:2017) specifies “Pronounced /ˈdʒeɪ.sən/, as in ‘Jason and The Argonauts'”. The first (2013) edition of ECMA-404 did not address the pronunciation. The UNIX and Linux System Administration Handbook states that “Douglas Crock ford, who named and promoted the JSON format, says it’s pronounced like the name Jason. But somehow, ‘JAY-sawn’ seems to have become more common in the technical community. Crock ford said in 2011, “There’s a lot of argument about how you pronounce that, but I strictly don’t care.
After RFC 4627 had been available as its “informational” specification since 2006, JSON was first standardized in 2013, as ECMA-404. RFC 8259, published in 2017, is the current version of the Internet Standard STD 90, and it remains consistent with ECMA-404. That same year, JSON was also standardized as ISO/IEC 21778:2017. The ECMA and ISO/IEC standards describe only the allowed syntax, whereas the RFC covers some security and interoperability considerations.
JSON grew out of a need for a stateless, real-time server-to-browser communication protocol without using browser plugins such as Flash or Java applets, the dominant methods used in the early 2000s.
Crockford first specified and popularized the JSON format. The acronym originated at State Software, a company co-founded by Crock ford and others in March 2001. The co-founders agreed to build a system that used standard browser capabilities and provided an abstraction layer for Web developers to create state ful Web applications that had a persistent duplex connection to a Web server by holding two Hypertext Transfer Protocol (HTTP) connections open and recycling them before standard browser time-outs if no further data were exchanged. The co-founders had a round-table discussion and voted whether to call the data format JSML (JavaScript Markup Language) or JSON (JavaScript Object Notation), as well as under what license type to make it available. The JSON.org website was launched in 2002. In December 2005, Yahoo! began offering some of its Web services in JSON.
A precursor to the JSON libraries was used in a children’s digital asset trading game project named Cartoon Orbit at Communities.com (the State co-founders had all worked at this company previously) for Cartoon Network, which used a browser side plug-in with a proprietary messaging format to manipulate DHTML elements (this system is also owned by 3DO). Upon discovery of early Ajax capabilities, digi Groups, Noosh, and others used frames to pass information into the user browsers’ visual field without refreshing a Web application’s visual context, realizing real-time rich Web applications using only the standard HTTP, HTML and JavaScript capabilities of Netscape 4.0.5+ and IE 5+. Crock ford then found that JavaScript could be used as an object-based messaging format for such a system. The system was sold to Sun Micro systems, Amazon.com and EDS.
JSON was based on a subset of the JavaScript scripting language (specifically, Standard ECMA-262 3rd Edition—December 1999) and is commonly used with JavaScript, but it is a language-independent data format. Code for parsing and generating JSON data is readily available in many programming languages. JSON’s website lists JSON libraries by language.
In October 2013, Ecma International published the first edition of its JSON standard ECMA-404. That same year, RFC 7158 used ECMA-404 as a reference. In 2014, RFC 7159 became the main reference for JSON’s Internet uses, superseding RFC 4627 and RFC 7158 (but preserving ECMA-262 and ECMA-404 as main references). In November 2017, ISO/IEC JTC 1/SC 22 published ISO/IEC 21778:2017 as an international standard. On 13 December 2017, the Internet Engineering Task Force obsoleted RFC 7159 when it published RFC 8259, which is the current version of the Internet Standard STD 90.
Crockford added a clause to the JSON license stating that “The Software shall be used for Good, not Evil,” in order to open-source the JSON libraries while mocking corporate lawyers and those who are overly pedantic. On the other hand, this clause led to license compatibility problems of the JSON license with other open-source licenses, as open-source software and free software usually imply no restrictions on the purpose of use.